Worked Example: Data Wrangling practice with coot chick color data
Dai Shizuka
updated 11/05/24
The goal of this worked example is to demonstrate how to combine multiple related datasets and organize data for plotting and analysis.
To demonstrate how dplyr functions work, we will use a
dataset from a project on color variation in American coots (Fulica
americana). This is data comes from Lyon &
Shizuka (2020) in PNAS. All of the data for this paper
(much more than we will use in this exercise!) is publicly available via
Dryad (here).
But to simplify things, I will provide the necessary datasets below.
First, let’s give you a quick background on the study system:
1. Background: Extreme juvenile ornamentation in American coots
American coots (Fulica americana), a waterbird of the Rail family. Coots lay a relatively large number of eggs (6-12 eggs) in nests built out of old vegetation on top of water in wetlands across western North America.
There are at least two very weird thing about coots: One weird thing is that they are ‘conspecific brood parasites’–i.e., they make their own nests, but they will also opportunistically lay eggs in their neighboring coot nests. Our research has shown that they can, under certain circumstances, tell which eggs and chicks in their nest are parasitic (Lyon 2003; Shizuka & Lyon 2010).
The other very weird thing is that they have extremely bright ornamental juvenile traits (red beaks, red head, orange plumes around the neck, etc.) when they hatch. They then lose these traits over the first few weeks of life. By the time they have fledged, they are black and gray with white beaks, and the only color they retain is a small patch or red on their forehead. Birds commonly have bright ornamental traits related to sexual selection, but it is relatively rare to have such bright ornaments as babies (probably because it could make them easy targets for predators).

Figure 1: Adult coots are black and gray with a white beak. Baby coots have bright ornamentation ranging from orange to red.
Past work (Lyon et al. 1994) has shown that, if you artificially remove some of these ornaments (i.e., the orange tips of feathers around neck), parents discriminate against these ‘dull’ chicks and preferentially feed chicks that retain the ornaments.
In Lyon & Shizuka (2020), we investigate the causes and consequences of variation in color (i.e., how ‘red’ the chicks are) within and between broods. We also link this data to patterns of parental favoritism and survival.
2: The Data
In this study, we monitored nests and eggs until hatching, and then measured color of juvenile ornaments using a spectrometer (which measures reflectance of light at different wavelengths) from ~1,500 chicks. For each chick, we got 3-5 measurements from 5 traits: pate (bald spot on top of their head), frontal shield (fleshy part at the base of the beak), papillae (ornamental feathers surrounding the base of the beak), beak, and feathers surrounding the chin and neck. We have condensed data to several key color metrics, including the ‘red chroma’ (i.e., amount of light reflected at the red wavelengths: approx 600-700nm) of the feathers around the chin. This is provided in the “ChickColor_extracted.csv” file.

Figure 2: We took color measurements for 5 different traits: pate, frontal shield, papillae, beak and chin feathers. (From Lyon & Shizuka 2020)
We also have a separate file of relevant (non-color) data for each chick, such “Egg ID”, which brood they were released at (the same as the nest the egg was laid in for control treatment, but chicks were swapped across nests in some experiments), the experimental treatment of the brood, the nest it was laid in as an egg (Clutch), the date it was released in the nest, the order in which they hatched in the nest/were released at the nest, the wetland the nest is in, and whether or not the chick is a known brood parasite.
Finally, we also have data for each chick as an egg, including nest, “Egg ID”, “Chick ID”, the volume of the egg, and the laying sequence of the egg (if known).
Here is the link to the data .zip file. Download this file and extract the contents. There should be three .csv files. Save these files in the “data” subfolder within the project folder you are working in.
First, load the packages you need
library(tidyverse)Then import this data to R:
eggs=read.csv("data/coot_example/EggMaster.csv")
tibble(eggs)## # A tibble: 4,623 × 6
## Nest Egg.Number Egg.ID Chick.ID Egg.Volume True.Lay.Seq
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 5001 1 5001-1 5001-1 30.9 1.5
## 2 5001 2 5001-2 5001-2 34.5 1.5
## 3 5001 3 5001-3 5001-3 35.0 3
## 4 5001 4 5001-4 5001-4 32.2 4
## 5 5001 5 5001-5 5001-5 34.4 5
## 6 5001 6 5001-6 5001-6 33.6 6
## 7 5001 7 5001-7 5001-7 32.8 7
## 8 5001 8 5001-8 5001-8 32.4 8
## 9 5001 9 5001-9 5001-9 32.2 9
## 10 5001 10 5001-10 5001-10 31.2 10
## # ℹ 4,613 more rowschicks=read.csv("data/coot_example/ChickMaster.csv")
tibble(chicks)## # A tibble: 2,465 × 10
## new.id Egg.ID Brood Brood.Treatment Clutch Release.Date Release.Order Wetland
## <chr> <chr> <int> <chr> <chr> <chr> <int> <chr>
## 1 5001-1 1 5001 Control 5001 5/31/09 1 Jaimes…
## 2 5001-3 3 5001 Control 5001 5/31/09 1 Jaimes…
## 3 5001-2 2 5001 Control 5001 6/1/09 2 Jaimes…
## 4 5001-4 4 5001 Control 5001 6/1/09 2 Jaimes…
## 5 5001-5 5 5001 Control 5001 6/1/09 2 Jaimes…
## 6 5001-6 6 5001 Control 5001 6/1/09 2 Jaimes…
## 7 5001-7 7 5001 Control 5001 6/1/09 2 Jaimes…
## 8 5001-8 8 5001 Control 5001 6/2/09 3 Jaimes…
## 9 5001-9 9 5001 Control 5001 6/3/09 4 Jaimes…
## 10 5001-… 10 5001 Control 5001 6/4/09 5 Jaimes…
## # ℹ 2,455 more rows
## # ℹ 2 more variables: Year <int>, is.parasite <lgl>color.dat=read.csv("data/coot_example/chickcolor_extracted.csv")
tibble(color.dat)## # A tibble: 1,459 × 16
## new.id beak_brightness beak_chroma beak_hue chin_brightness chin_chroma
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 5001-1 10115. 0.853 582. 12648. 0.666
## 2 5001-10 10978. 0.795 594. 9211. 0.700
## 3 5001-11 10969. 0.861 589. 11616. 0.743
## 4 5001-12 9498. 0.750 593. 10057. 0.693
## 5 5001-2 9923. 0.804 594. 7949. 0.605
## 6 5001-3 14946. 0.764 579. 8907. 0.678
## 7 5001-4 11380. 0.813 587. 9092. 0.642
## 8 5001-5 14091. 0.778 591. 10383. 0.721
## 9 5001-6 11434. 0.760 588. 6023. 0.719
## 10 5001-7 9370. 0.867 586. 14346. 0.737
## # ℹ 1,449 more rows
## # ℹ 10 more variables: chin_hue <dbl>, papillae_brightness <dbl>,
## # papillae_chroma <dbl>, papillae_hue <dbl>, pate_brightness <dbl>,
## # pate_chroma <dbl>, pate_hue <dbl>, shield_brightness <dbl>,
## # shield_chroma <dbl>, shield_hue <dbl>3. Correlations between color traits (Figure 1)
I will select just the columns of the color data that contains the word “chroma”. Then, I will rename the variables to add a number in front of the name. This will just help me customize the order of the rows and columns on the matrix that I generate.
chroma.dat=color.dat %>% dplyr::select(contains("_chroma")) %>%
rename(`5_pate`=pate_chroma, `4_shield`=shield_chroma, `3_beak`=beak_chroma, `2_papillae`=papillae_chroma, `1_chin`=chin_chroma)set up correlation matrix for plotting
cor.m=cor(chroma.dat, use="complete.obs")
cor.m=cor.m[order(rownames(cor.m)),order(rownames(cor.m))] #reorder columns and rowsConvert the data in the correlation matrix into a two-column format that ggplot likes.
cor.data.frame=data.frame(expand.grid(colnames(cor.m), rownames(cor.m)), value=as.vector(cor.m))generate correlation plots for chroma
ggplot(cor.data.frame, aes(x=Var1, y=Var2, fill=value)) +
geom_tile() +
scale_fill_gradient2(limits=c(0, 1), low="white", high="red")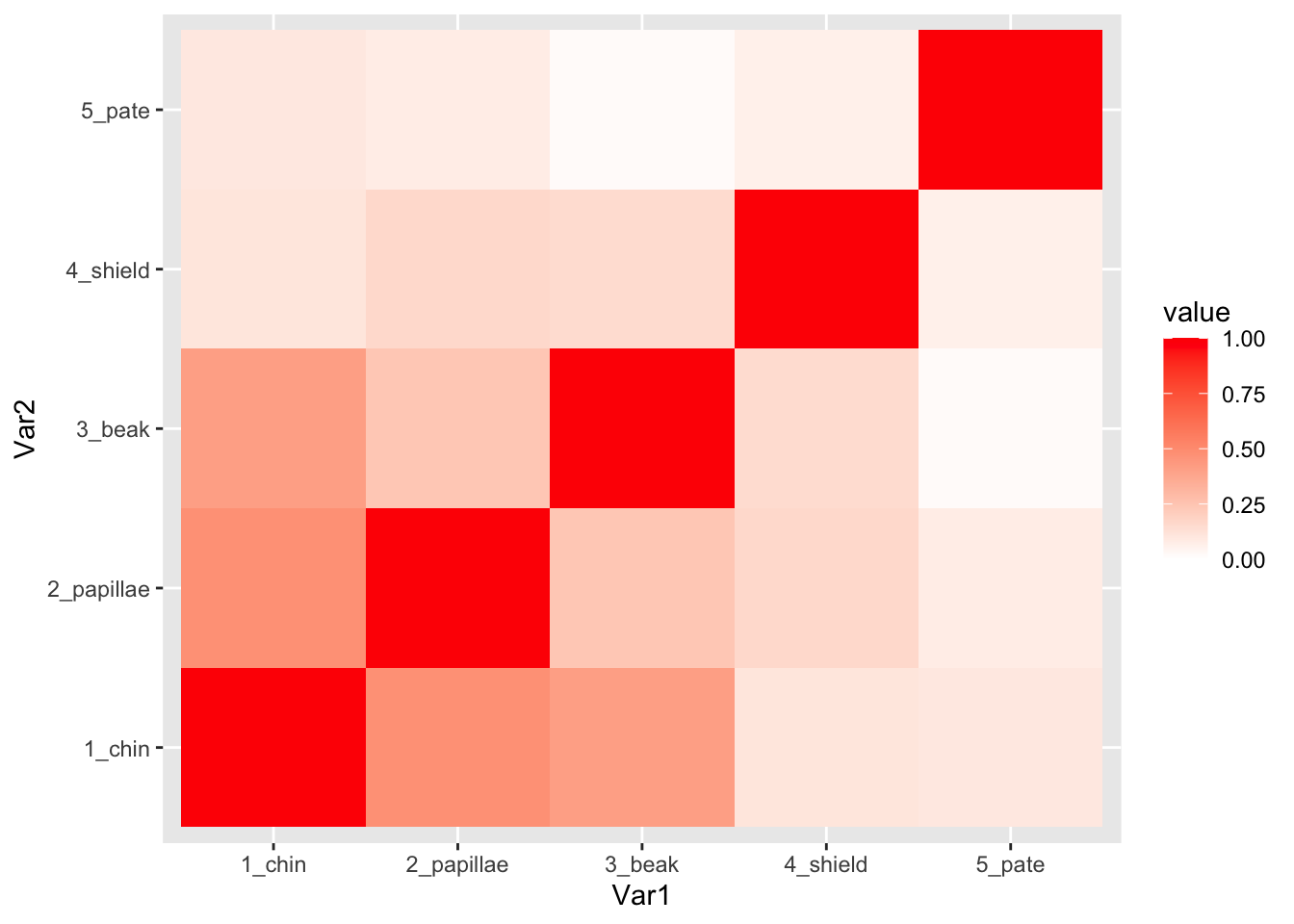
4. Analyze how chick colors differ between broods (Table 1)
4.1. Make a global dataset that contains chick color, chick master, and egg data
We are going to use a set of left_join() functions to
create a global dataset.
all.dat=left_join(chicks, color.dat, by=join_by(new.id==new.id)) %>%
left_join(., eggs, by=join_by(new.id==Chick.ID)) %>%
tibble()4.2. Conduct PCA to get a color variable
One problem with having measured a lot of different color variables is that
Only chick color data variables contain “_”
pca.result=all.dat%>% select(contains("chin"), contains("papillae"), contains("beak")) %>% drop_na() %>% prcomp(., center=T, scale=T)You can look at the details of the prcomp() function
using ?prcomp. Under “Value” in the help file, you’ll see
that this function returns a list in which “x” is the rotated data. We
can check out a little bit of that matrix:
#just look at the "upper left corner" of the PCA results, which is stored in the pca.result object
pca.result$x[1:10, 1:5]## PC1 PC2 PC3 PC4 PC5
## [1,] 0.15563752 -0.9096121 -0.5551098 0.2240269 0.7313733
## [2,] -1.08256364 1.0799289 0.9836269 0.9390664 1.2726829
## [3,] -0.88700758 1.4117492 -2.2472509 -0.2587771 1.0359437
## [4,] -0.42522677 0.7434949 -0.8975176 0.7476596 1.0716827
## [5,] 0.01855970 0.9858997 0.4679448 1.9539550 0.1464993
## [6,] 2.55414248 2.2694434 0.6576348 0.4348294 0.8414584
## [7,] 0.47403292 -2.3134839 -0.3599670 2.3396399 -0.4639107
## [8,] 0.37483620 0.2428154 1.4383682 1.2333483 -0.3268253
## [9,] 0.07805023 0.9279929 -0.8234554 1.3611125 1.2913388
## [10,] 2.98404071 -0.2299321 0.5409242 1.0688361 0.0353071We can extract the first PCA axis as the first column of this object:
head(pca.result$x[,1])## [1] 0.1556375 -1.0825636 -0.8870076 -0.4252268 0.0185597 2.5541425Now that we know how to get the PC1 variable, we will create a new
data subset, which we will call use.dat that includes the
chick ID, the clutch (i.e., nest) it came from, and the color variables
(i.e., all variables that include “_“) and the PC1 variable. We want to
also convert Clutch into a factor (it is currently classified as
Character).
use.dat = all.dat %>%
select(new.id, Clutch, contains("beak"), contains("papillae"), contains("chin")) %>%
drop_na() %>%
mutate(pc1=pca.result$x[,1]) %>%
mutate(Clutch=factor(Clutch)) Table 1
Now, we can use an apply function sapply() to run ANOVAs
with each color variable as the response variable, and clutch as the
predictor variable. To do this, we will first define which columns of
the data are the color variables (i.e., all variables that include “_”
in the name, as well as the one that includes “pc” in the name). Then,
we will use the sapply() function to run the ANOVA with
each variable in turn.
Note: One difference between data.frame and tibble is how we call variables using their column name. In dataframe, we would use the single square bracket to index, so we would call the third column as: df$[,1]. In tibble, we use the double square bracket: df[[3]].
color.columns=as.numeric(c(grep("_",colnames(use.dat)), grep("pc", colnames(use.dat))))
aov.results=sapply(color.columns, function(x) summary(aov(use.dat[[x]]~as.factor(use.dat$Clutch))))For kicks, here is an alternative version using a for loop (result not shown, but it would look the same):
color.columns=as.numeric(c(grep("_",colnames(use.dat)), grep("pc", colnames(use.dat))))
aov.results=list()
for (i in 1:length(color.columns)){
aov.results[[i]]=summary(aov(use.dat[[color.columns[i]]]~as.factor(use.dat$Clutch)))
}Now, we can extract the F values and P values (and calculate P values
adjusted for False Discovery Rate) from the aov.results
object (i.e., list of ANOVA model fits) and organize them into a
table.
result.dat=data.frame(trait=names(use.dat)[color.columns], Fvalue=round(sapply(1:length(color.columns), function(x) aov.results[[x]]$`F value`[1]), digits=3), Pvalue=round(sapply(1:length(color.columns), function(x) aov.results[[x]]$`Pr(>F)`[1]), digits=5))
result.dat$p.adjust=p.adjust(result.dat$Pvalue, method="fdr")
result.dat #Table 1## trait Fvalue Pvalue p.adjust
## 1 beak_brightness 2.254 0 0
## 2 beak_chroma 2.528 0 0
## 3 beak_hue 2.167 0 0
## 4 papillae_brightness 1.959 0 0
## 5 papillae_chroma 2.215 0 0
## 6 papillae_hue 2.775 0 0
## 7 chin_brightness 2.758 0 0
## 8 chin_chroma 4.234 0 0
## 9 chin_hue 3.941 0 0
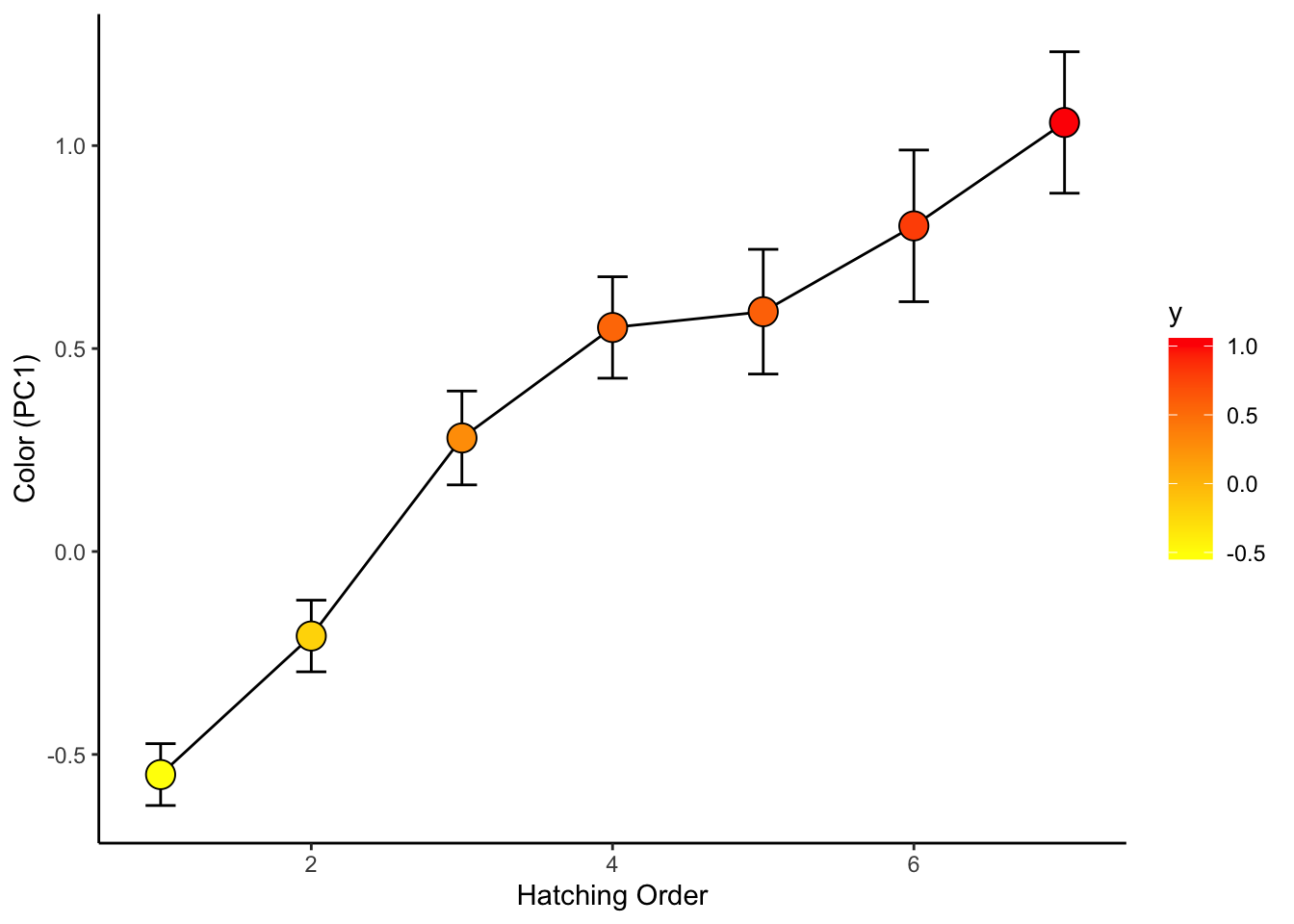
## 10 pc1 4.965 0 05. See how chick coloration is affected by hatching sequence
use.dat2=left_join(all.dat, use.dat, by="new.id") %>%
select(new.id, Brood, Release.Order, is.parasite, pc1) %>%
mutate(Release.Order=replace(Release.Order, Release.Order>7, 7)) %>%
drop_na()## Warning in left_join(all.dat, use.dat, by = "new.id"): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 86 of `x` matches multiple rows in `y`.
## ℹ Row 81 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.ggplot(use.dat2, aes(x=factor(Release.Order), y=pc1)) +
geom_boxplot()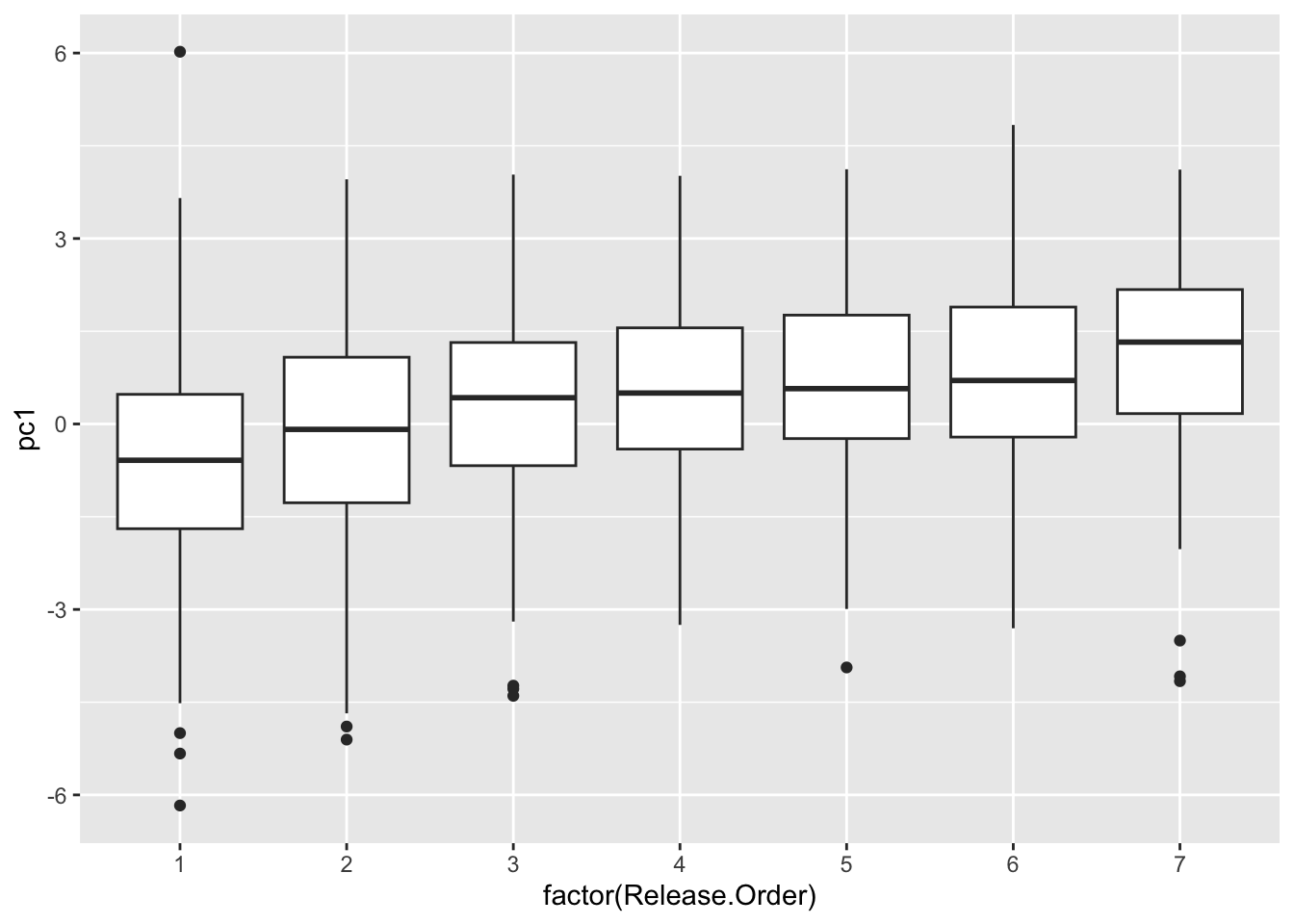
ggplot(use.dat2, aes(x=factor(Release.Order), y=pc1, fill=Release.Order)) +
geom_boxplot() +
scale_fill_gradient(low="yellow", high="red")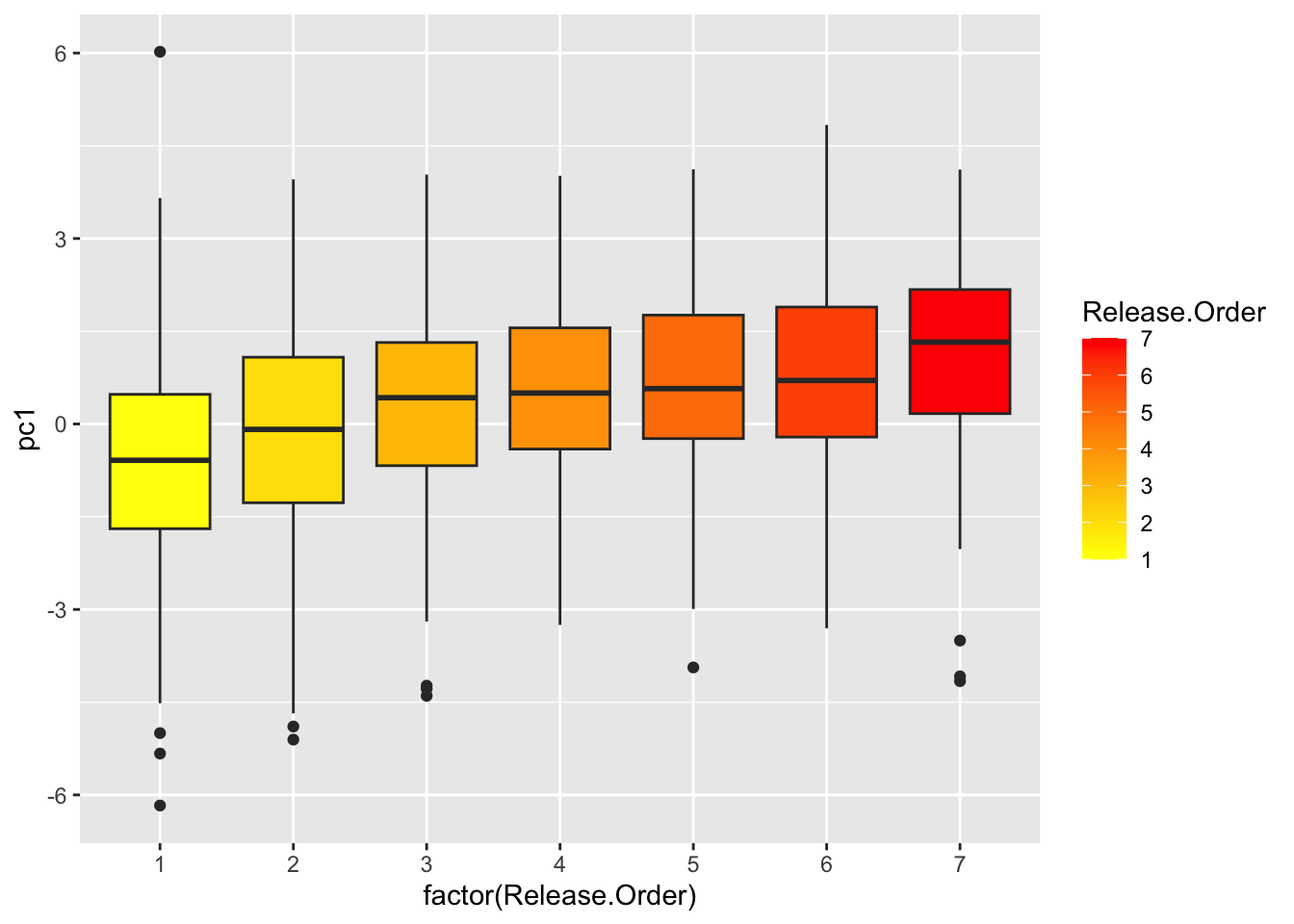
sum.dat=use.dat2 %>%
group_by(Release.Order) %>%
summarise(mean_se(pc1))ggplot(sum.dat, aes(x=Release.Order, y=y, fill=y)) +
geom_path() +
geom_errorbar(aes(ymax=ymax, ymin=ymin), width=0.2) +
geom_point(size=5, pch=21) +
scale_fill_gradient(low="yellow", high="red") +
theme_classic() +
ylab("Color (PC1)") +
xlab("Hatching Order")